Knowledge Base
Knowledge bases allow you to upload private domain-specific data. When content is uploaded to a knowledge base, documents are automatically parsed and processed. AI applications "trained" with knowledge bases (by binding knowledge bases to agents) can retrieve and utilize relevant knowledge corpus when responding to user queries, providing targeted answers.
Knowledge bases must be bound to knowledge base agents to take effect. After binding a knowledge base, the agent can provide customized intelligent Q&A services based on the uploaded knowledge data, addressing the shortcomings of general large language models that lack domain data support and occasionally "hallucinate." With knowledge bases, you can upload product manuals, customer service FAQs to create intelligent customer service; upload your personal resume to create a "digital twin"; or even upload a novel to shape a character. Teach knowledge to a "digital brain" and let it become your "domain expert"!
1. Creating a Knowledge Base
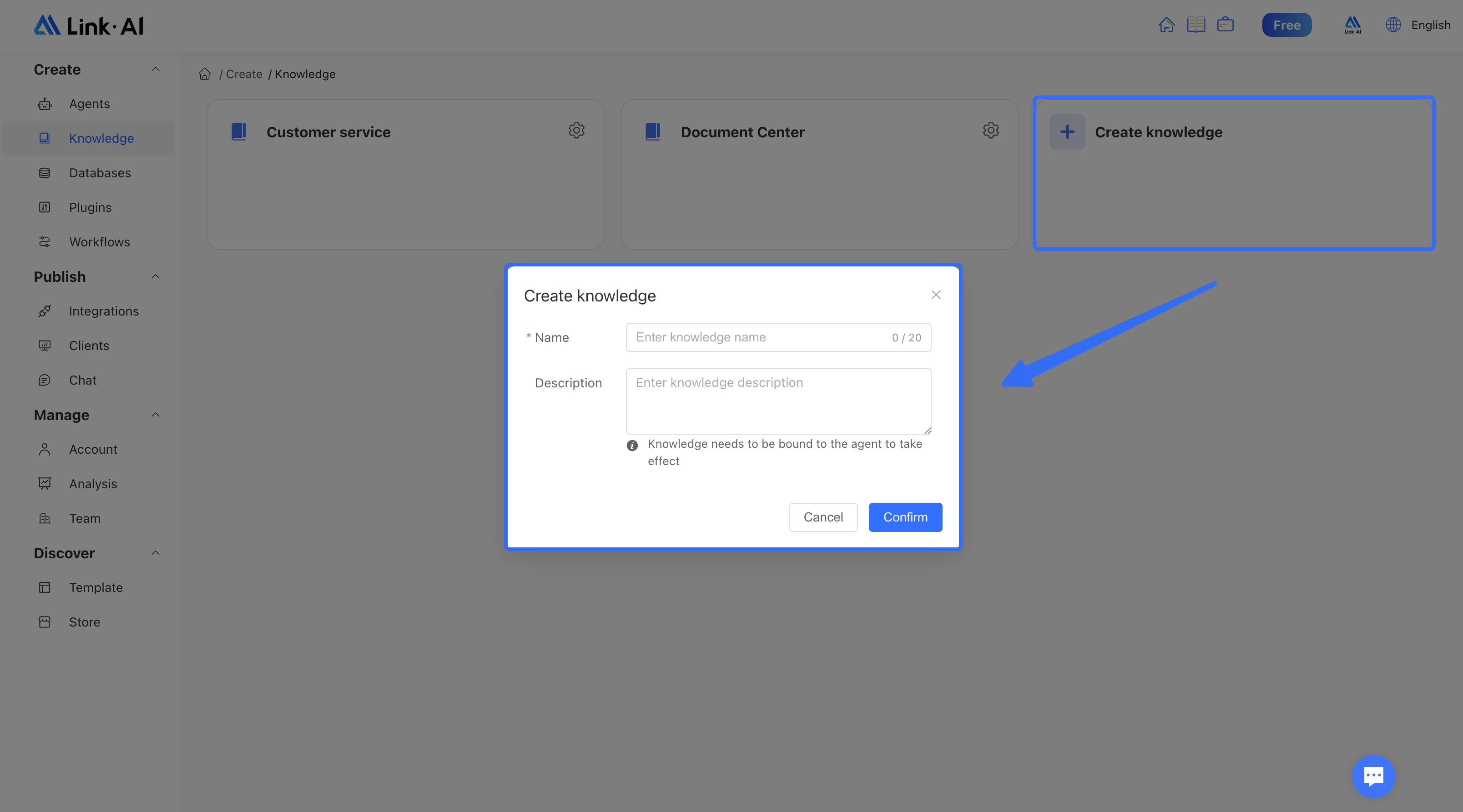
Go to the Knowledge Base menu, click "Create Knowledge Base," and enter a name and description to create a new knowledge base:
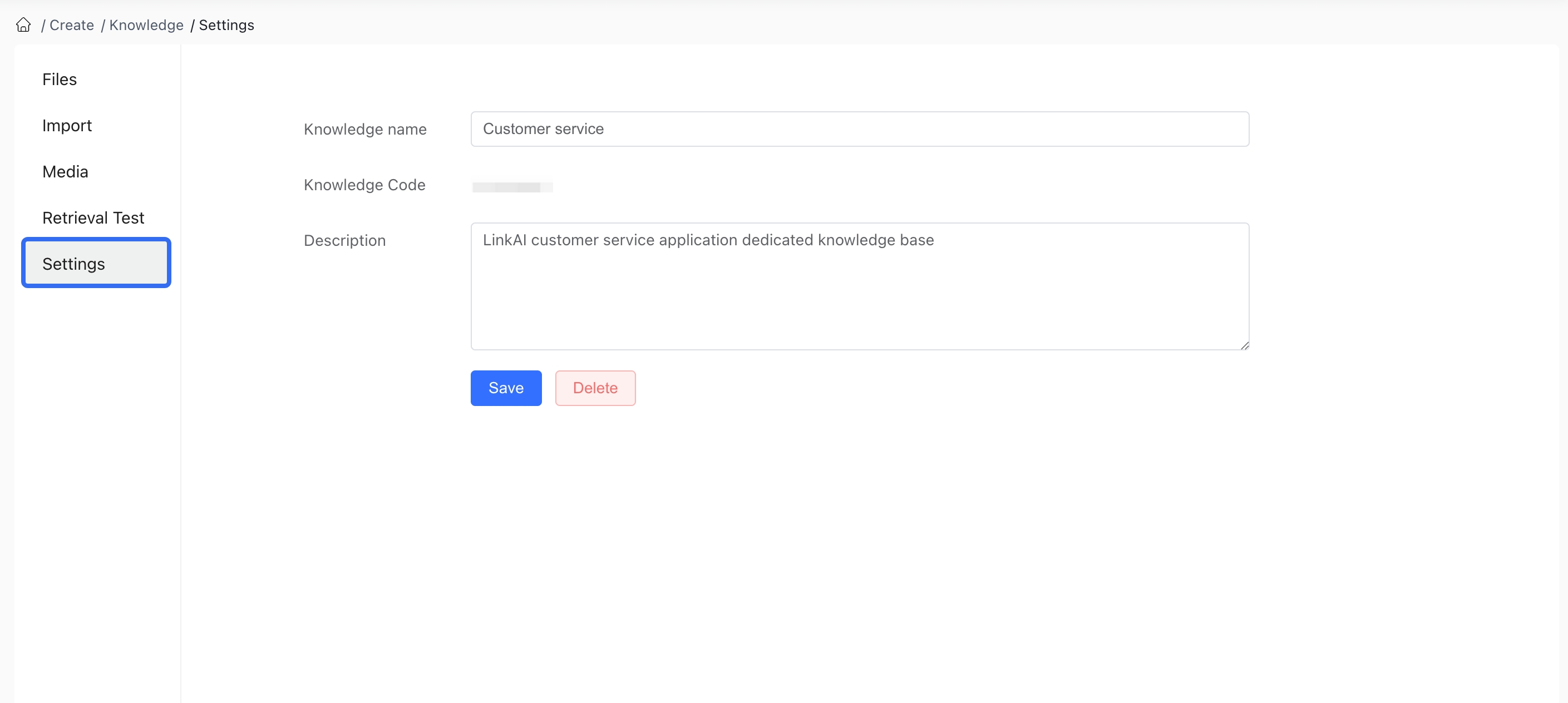
Click on the knowledge base to enter it, select the "Configuration" page to modify basic information or delete the knowledge base:
2. Importing Files
After creating a knowledge base, you can import knowledge content. Four types of knowledge are supported:
- Documents: Original documents that don't require any preprocessing. LinkAI will help you split and process the documents. Supports pdf, docx, md, txt, and single-column CSV formats.
- Q&A: Question-answer format content that needs to be preprocessed according to the template. Supports dual-column csv (question-answer) format.
- Tables: Multi-column Excel or CSV data tables. You can set which columns participate in indexing. Supports multi-column Excel or multi-column CSV formats.
- Website Import: Submit website URLs or sitemaps to automatically parse webpage content and import it into the knowledge base.
How should you choose between Documents, Q&A, Tables, and Website Import?
The choice depends on your existing knowledge structure and application scenario. Document import is very convenient, allowing you to directly upload pdf, word, and other files with automatic parsing and segmentation. Importing Q&A format provides higher accuracy in answers. Structured multi-column tables are common in certain business scenarios (such as product information tables with multiple SKUs and attributes). Website import allows you to directly parse and import online content from blogs, product manual websites, public account articles, etc.
You can combine multiple file import methods to achieve better results. For example, in customer service scenarios, you can organize customer service FAQs into Q&A format to ensure accurate answers to high-frequency questions. For multi-column product information tables or service description tables, you can import them as tables to provide precise information retrieval based on multiple columns. For more open-ended conversation scenarios, you can import company introductions, product descriptions, and usage guides as unstructured documents. Import personal blogs, company websites, and other online URLs through website parsing to cover long-tail questions and reduce the no-result rate.
A single knowledge base can contain all four different types of content: Documents, Q&A, Tables, and Website Import.
2.1 Unstructured Documents
When importing unstructured documents, the system automatically combines segment length and punctuation to split long text into multiple paragraphs for easier retrieval. You can preview the segmentation effect on the right. At the bottom left, you can see the token count of the file and the estimated credit cost:
When importing, you can choose to enable Enhanced Parsing, which can extract images or tables from imported pdf and docx documents into the knowledge base.
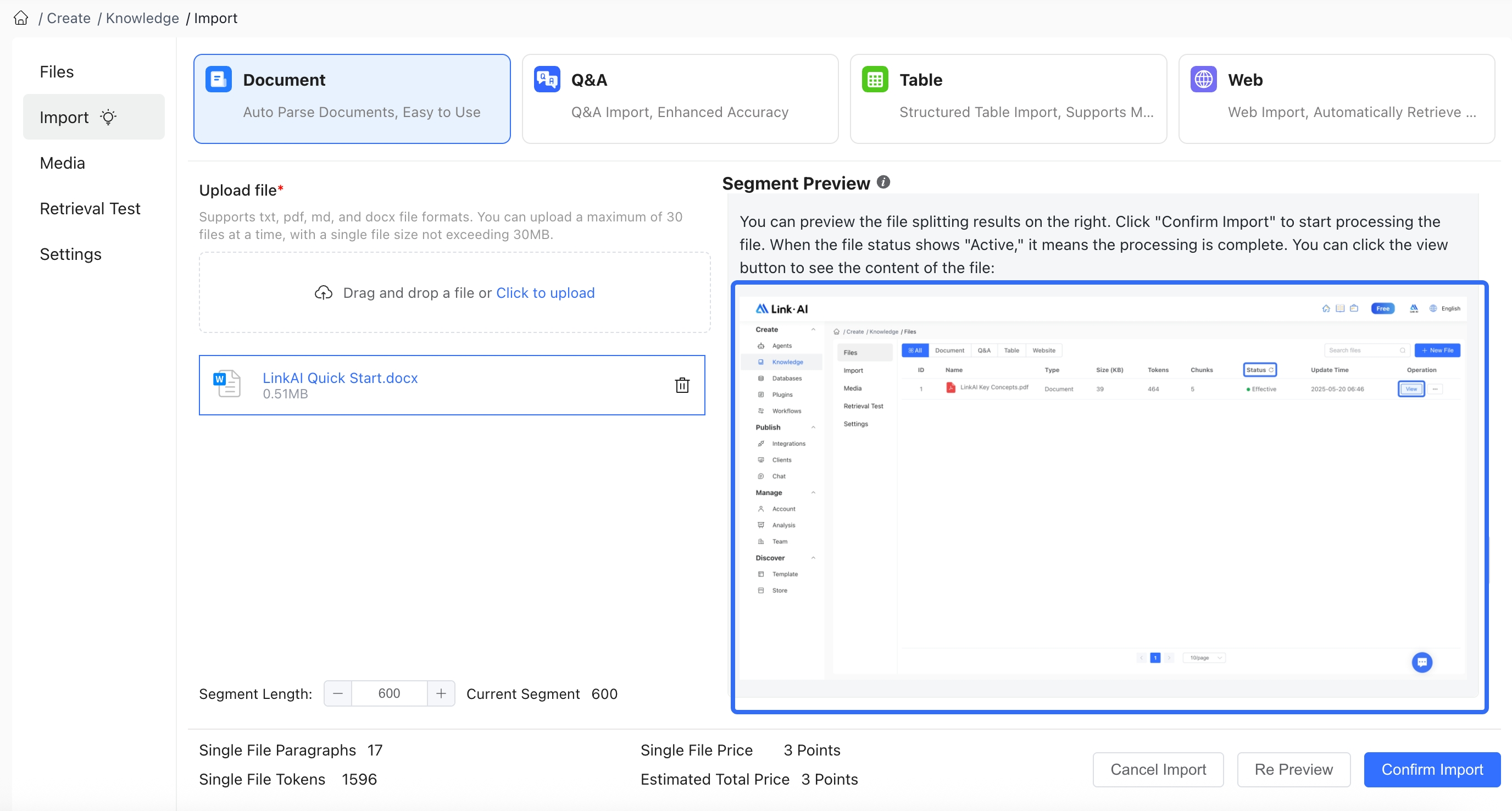
You can also set the segment length. Note that the segment length should not be set too large, as AI will retrieve several paragraphs and place them in the context when responding. If the paragraph content is too long or the number of paragraphs is too large, it may exceed the model's context limit.
For importing from Feishu Cloud Documents, please refer to the instructions in Feishu Import.
2.2 Q&A Pairs
To import Q&A pairs, download the CSV file template and fill it out according to the format. Each row has two columns: question and answer:
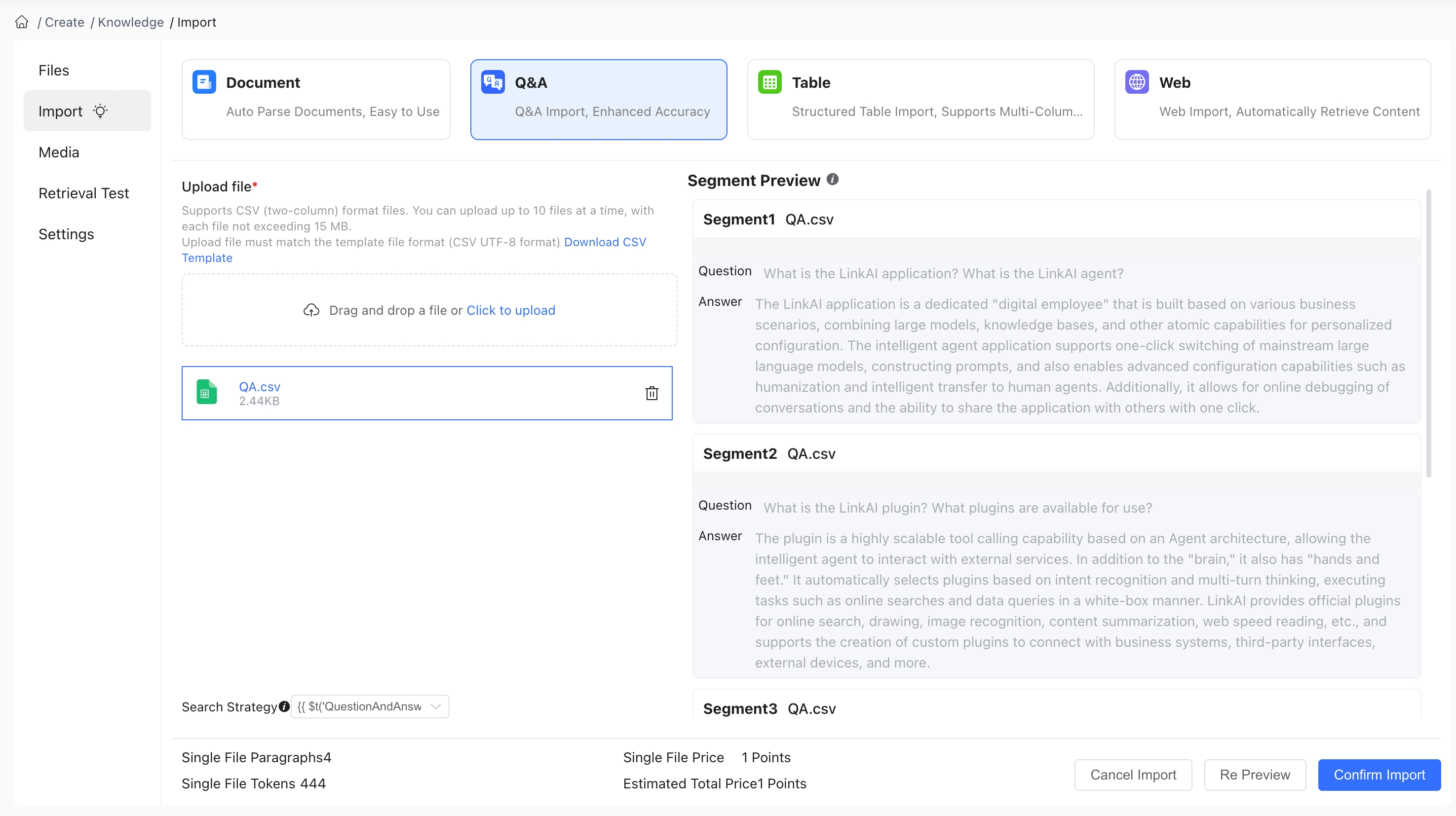
Unlike unstructured documents, Q&A type documents allow you to select a retrieval strategy during import:
- The default is "Search both questions and answers": Retrieval will match both the question and answer in the corpus, providing broader retrieval but lower similarity.
- You can choose "Search questions only": Retrieval will only find corpus entries based on text related to the question, providing higher retrieval similarity.
Suppose you have a Q&A entry with Question: "What types of agents does LinkAI have?" and Answer: "Lightweight and Knowledge Base"
If you select the "Search both questions and answers" strategy:
- When asked "What types of agents does LinkAI have?": The retrieval similarity might be 0.9, finding this entry and responding.
- When asked "What is a lightweight agent?", the retrieval similarity might be 0.85, still finding this entry and responding.
If you select the "Search questions only" strategy:
- When asked "What types of agents does LinkAI have?", the similarity would be 1, precisely finding this entry and responding.
- But if the question is "What is a lightweight agent?", the retrieval similarity might only be 0.7, possibly failing to match the entry and respond.
So, if your scenario primarily involves finding answers based on questions, and you don't need to find entries based on answer content, the "Search questions only" strategy will be more precise, and vice versa.
2.3 Multi-column Tables
Table import supports multi-column CSV files or Excel files. To avoid format issues, it's recommended to use CSV files (CSV UTF-8 format) for import:
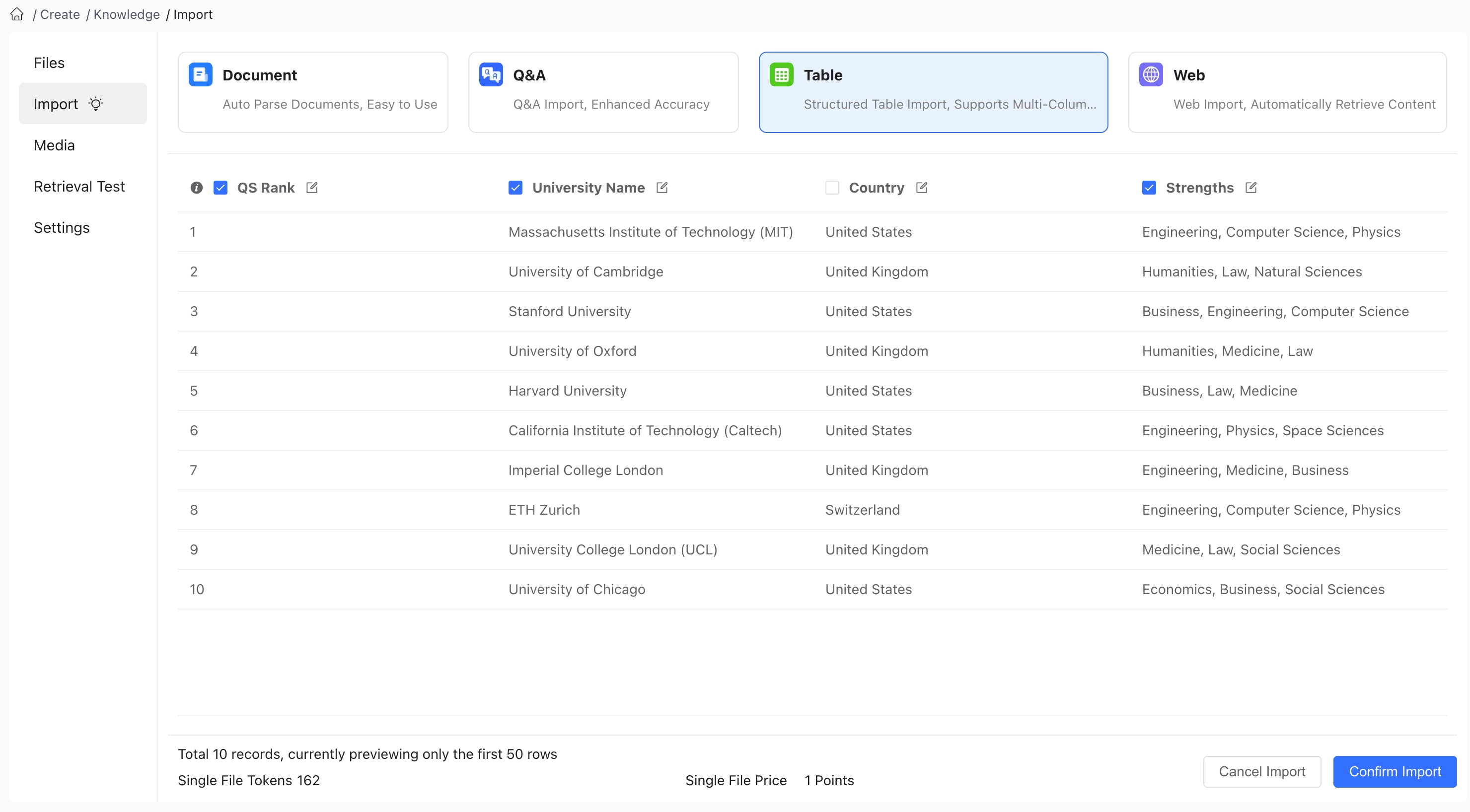
When importing tables:
- If an Excel file has multiple sheets, Sheet1 data is imported by default
- The first row of data will be used as headers (column names)
- For merged cells, the data in the merged cell will be filled into the original cell in the upper left
After importing a table:
- You can edit and modify column names (headers). Column names play an important semantic role in the retrieval and AI response generation process. Setting clear, meaningful column names helps the AI better understand the content of each column.
- You can set which columns participate in retrieval. By default, all column content participates in retrieval.
Index columns (columns that participate in retrieval) are those where user questions will be semantically matched or keyword-matched with the column content. Non-participating columns don't mean their content won't be searched when users ask questions.
Using the example above: If you set the "School English Name" column to not participate in retrieval, while the other three columns do participate, when a user's question involves "Oxford University," the user's question will be matched against the "Ranking," "School Name," and "Type" columns, retrieving the third row of data "1 Oxford University University of Oxford QS200". When the AI responds to the user, this entire row of data will be used for response generation.
For importing from Feishu Online Spreadsheets, please refer to the instructions in Feishu Import.
2.4 Website Import
Website import makes it easy to quickly import web resources into your knowledge base. When using the "Website Import" feature, the website addresses you submit should be websites you have the right to use or third-party URLs that you take full responsibility for the legality of. The platform only provides website parsing and import services and takes no responsibility for your use of the URL data. We recommend importing blogs, public account articles, official websites with primarily text information, instruction manuals, and other static resource websites. We do not support importing online documents, most platform-based media websites, or websites that require login.
Website import supports pasting single or batch independent URL links or directly entering a sitemap URL (a sitemap is a collection of webpage addresses set up by website administrators to facilitate search engine crawling, usually with a URL like the site's root address followed by /sitemap.xml), allowing you to retrieve text content from various subpages of the site with one click.
Similar to file import, the system automatically combines segment length and punctuation to split long text into multiple paragraphs for easier retrieval. You can preview the segmentation effect on the right:
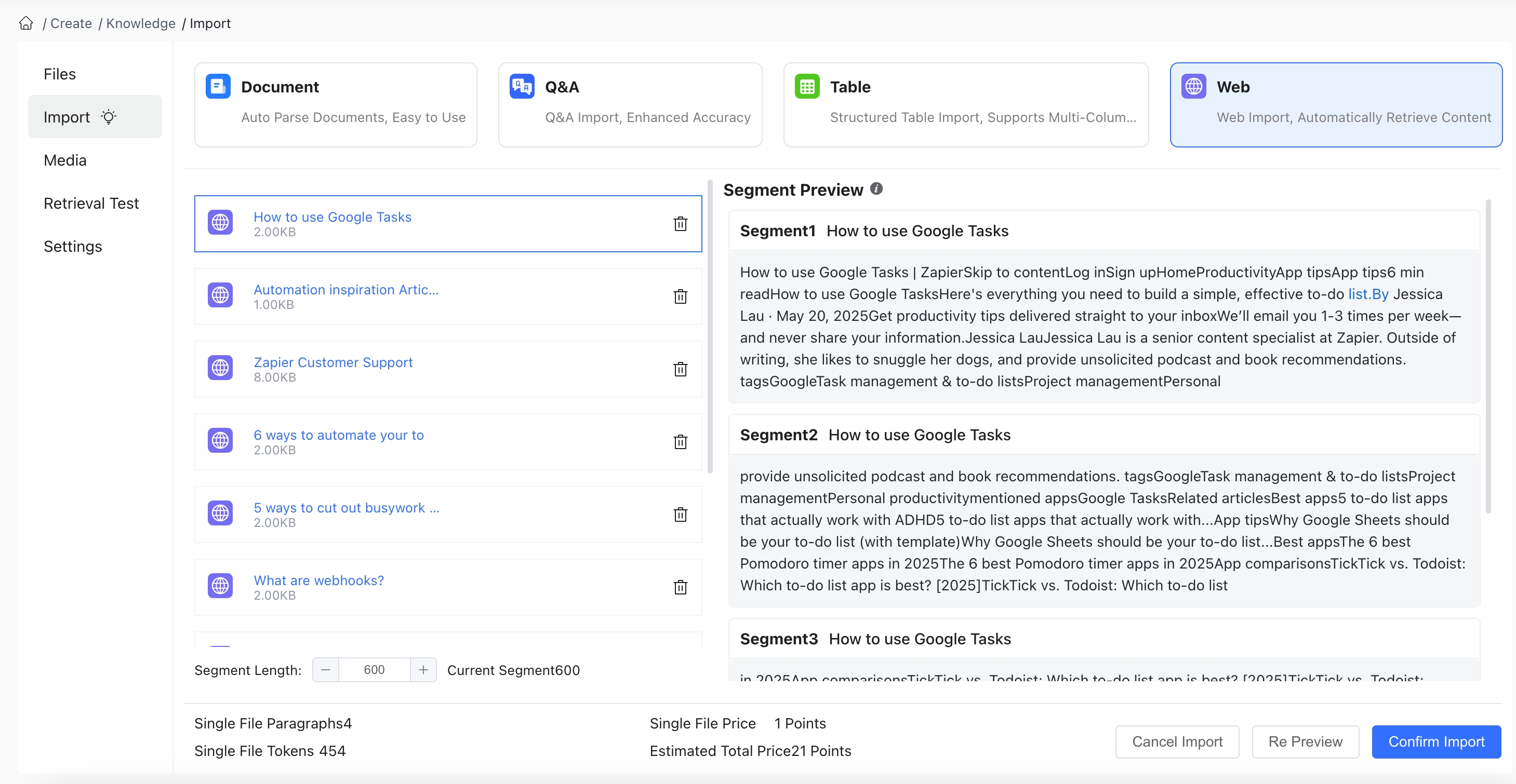
2.4.1 Independent URL Import
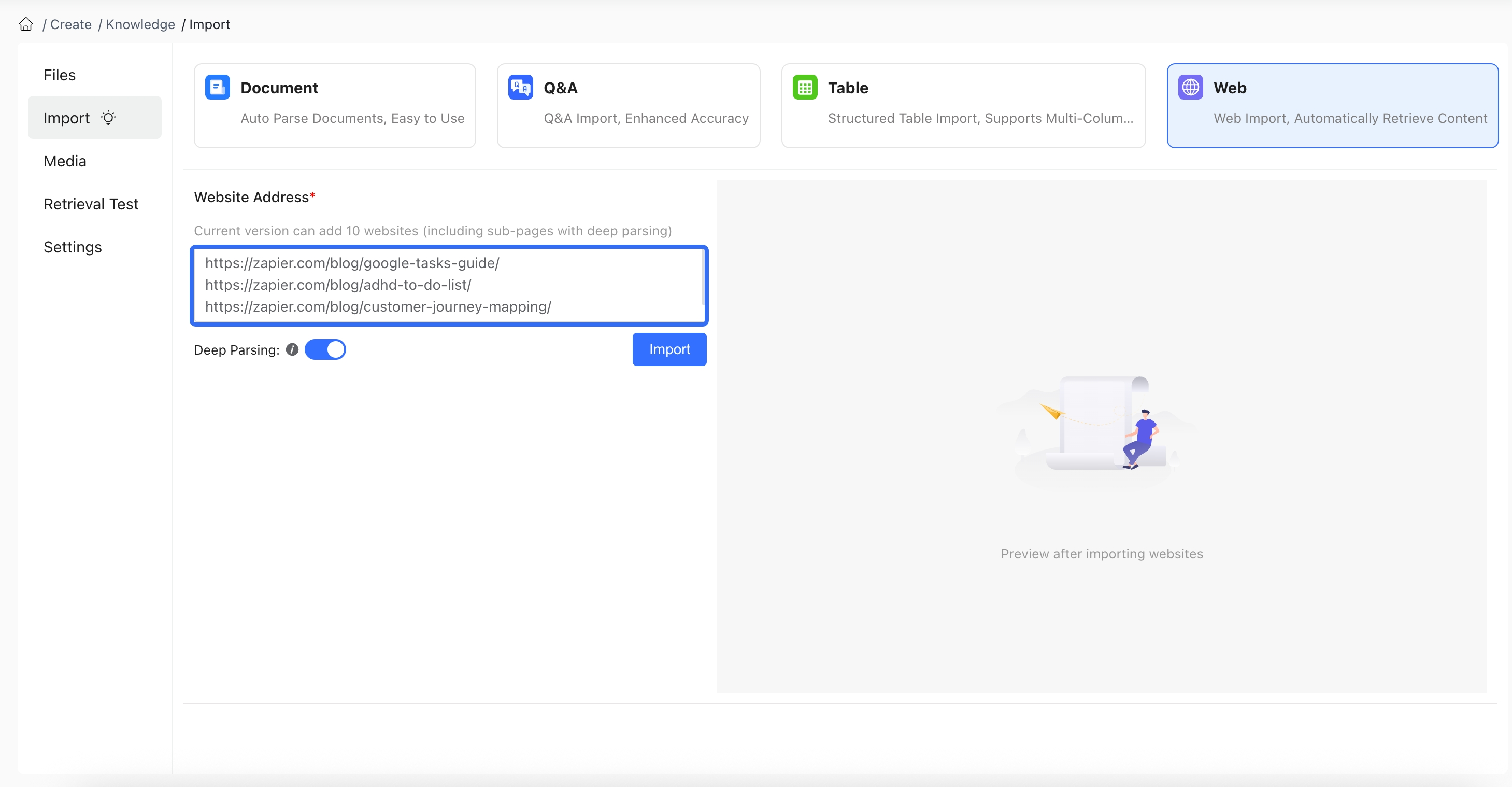
When importing, select "Batch import independent URLs" to paste multiple URL links separated by line breaks into the input box. Click import to view successfully imported webpages and preview content segmentation on the right. Unsupported webpages will be highlighted in red after the import operation:
Before importing, you can enable Extract Subpages in the lower left corner of the input box to automatically parse sublinks on the page and access their content, quickly importing subpages of the site through multi-level recursion. Enable Extract Images to extract images from the webpage for preview and store them as links in the knowledge base materials.
Knowledge Base Import Entitlements
| Category | Basic Plan | Standard Plan | Professional Plan |
|---|---|---|---|
| Files per import | 10 | 15 | 30 |
| File size limit | 15MB | 20MB | 30MB |
| Rows per table file | 2000 | 5000 | 10000 |
| Webpages per import (including deep-parsed sublinks) | 10 | 20 | 30 |
| Sitemap import webpage limit | 20 | 50 | 100 |
3. Uploading Materials
Knowledge bases support uploading additional materials for corpus paragraphs (supporting images, videos, files, mini-program cards, WeChat contact cards). When responding, if the knowledge base corpus used contains materials, the materials will be sent along with the response and displayed directly on the web page or channel end in the corresponding format (i.e., directly sending images, videos, mini-programs, etc.).
When adding image, video, file (pdf, ppt, word, excel, csv, txt, md) materials, you can directly upload them on the knowledge base corpus editing page, and the system will automatically convert them to links in the corpus content; or you can upload them in Knowledge Base - Material Management, then copy the material link and paste it into the editing box of the corresponding knowledge base corpus.
When a user's question matches that corpus, the AI bot will directly send out the materials. (To ensure stable material sending, you need to add the instruction in the application configuration - "Application Settings" (large model prompt) or workflow - large model node - "System Prompt": Send images, videos, and file links in the knowledge base information directly, without omitting or rewriting, and don't use markdown format.)
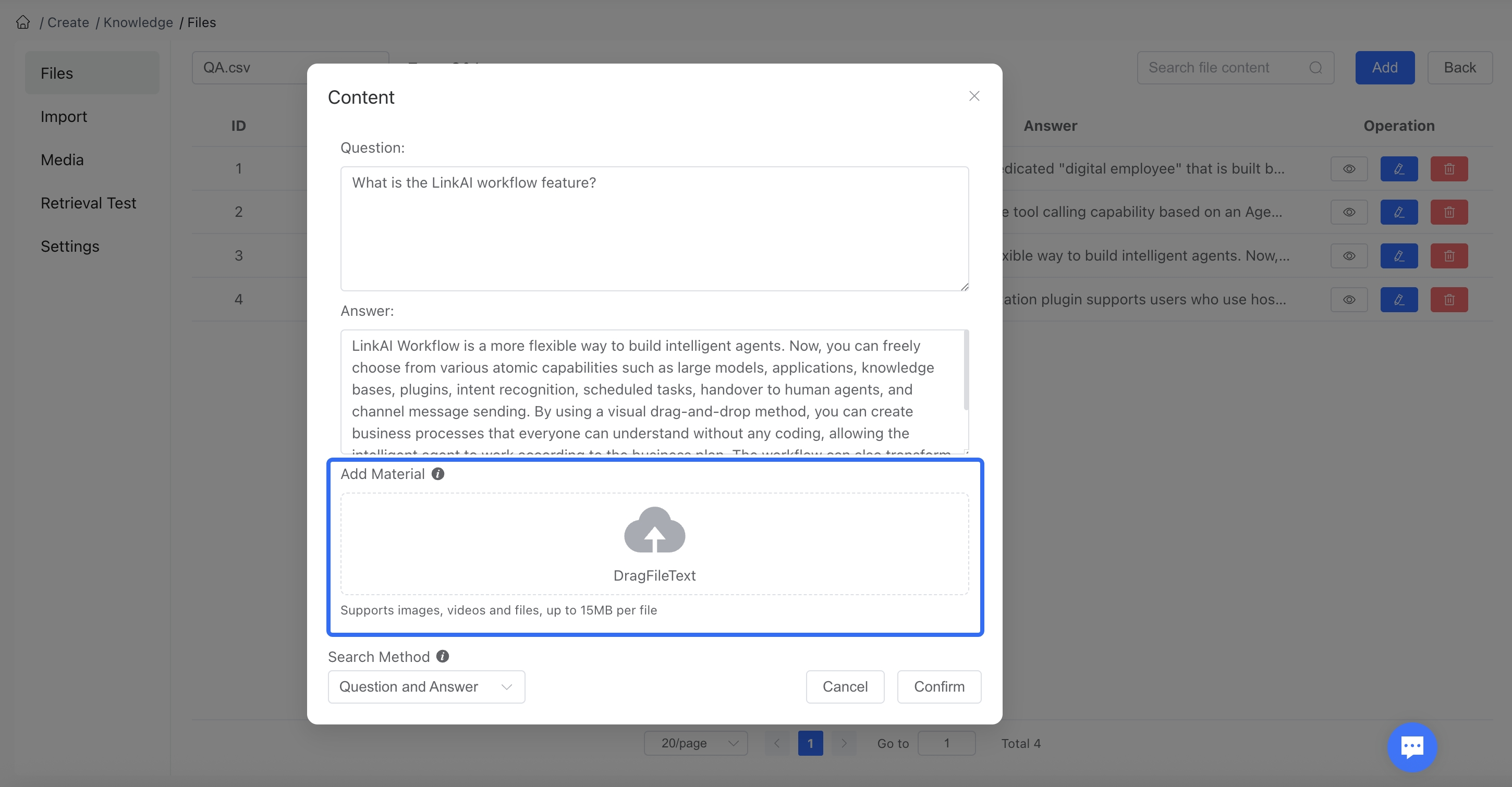
If you enable the Enhanced Parsing feature when importing documents, images extracted from documents will be automatically uploaded to the knowledge base material management.
4. Editing Content
After successful import, you can see the active files in the "File List." Click "View" to see the specific content of the file:
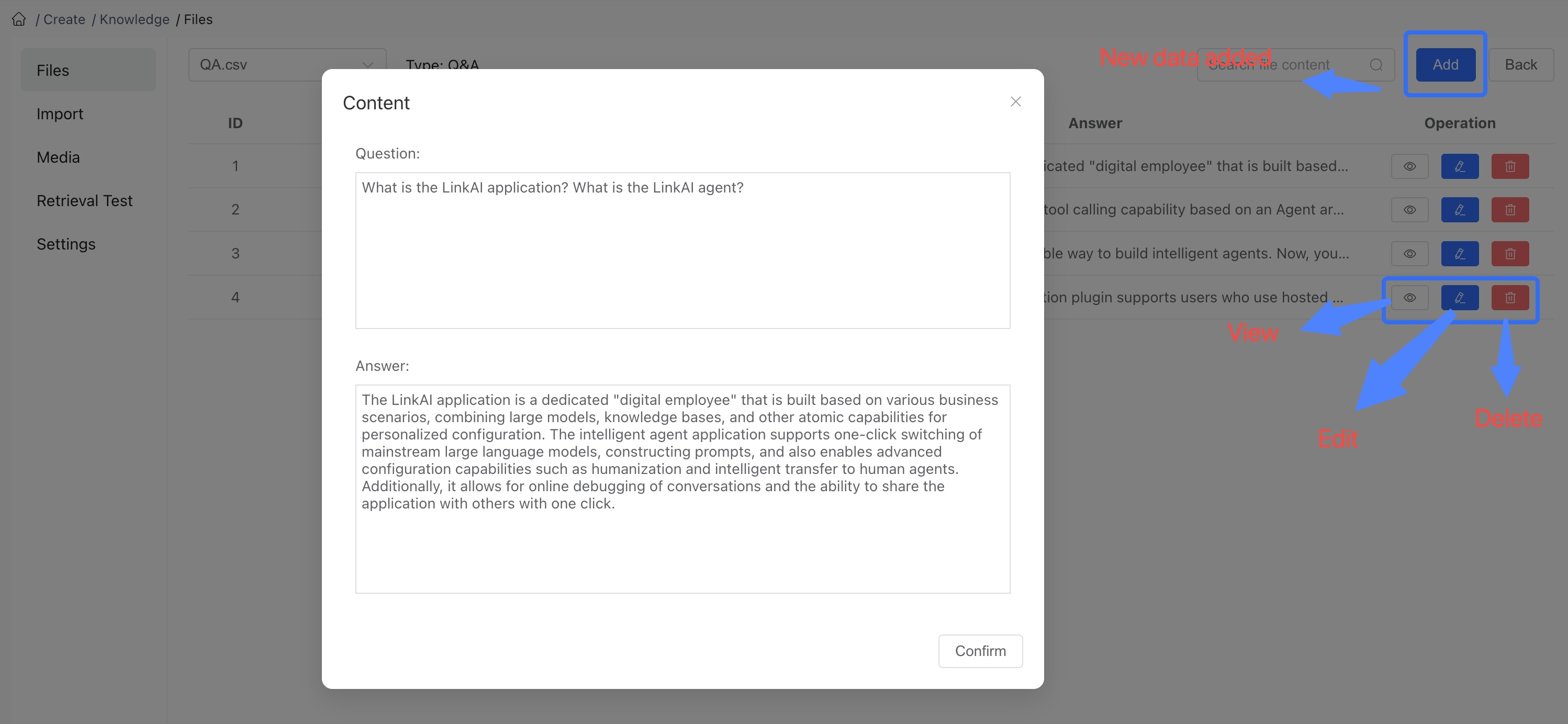
You can also edit, delete, and add individual entries to the file. Data change operations are performed asynchronously, so changes may not appear immediately on the page, but will be synchronized within a few seconds.
5. Configuring Retrieval Strategy and Starting Use
Knowledge bases need to be bound to an Agent or used in a workflow Knowledge Base Node to be effective. One agent can bind multiple knowledge bases, and one knowledge base can be bound to multiple agents.
For using knowledge base capabilities in the "Knowledge Base" node of a workflow, see: Workflow-Knowledge Base Node
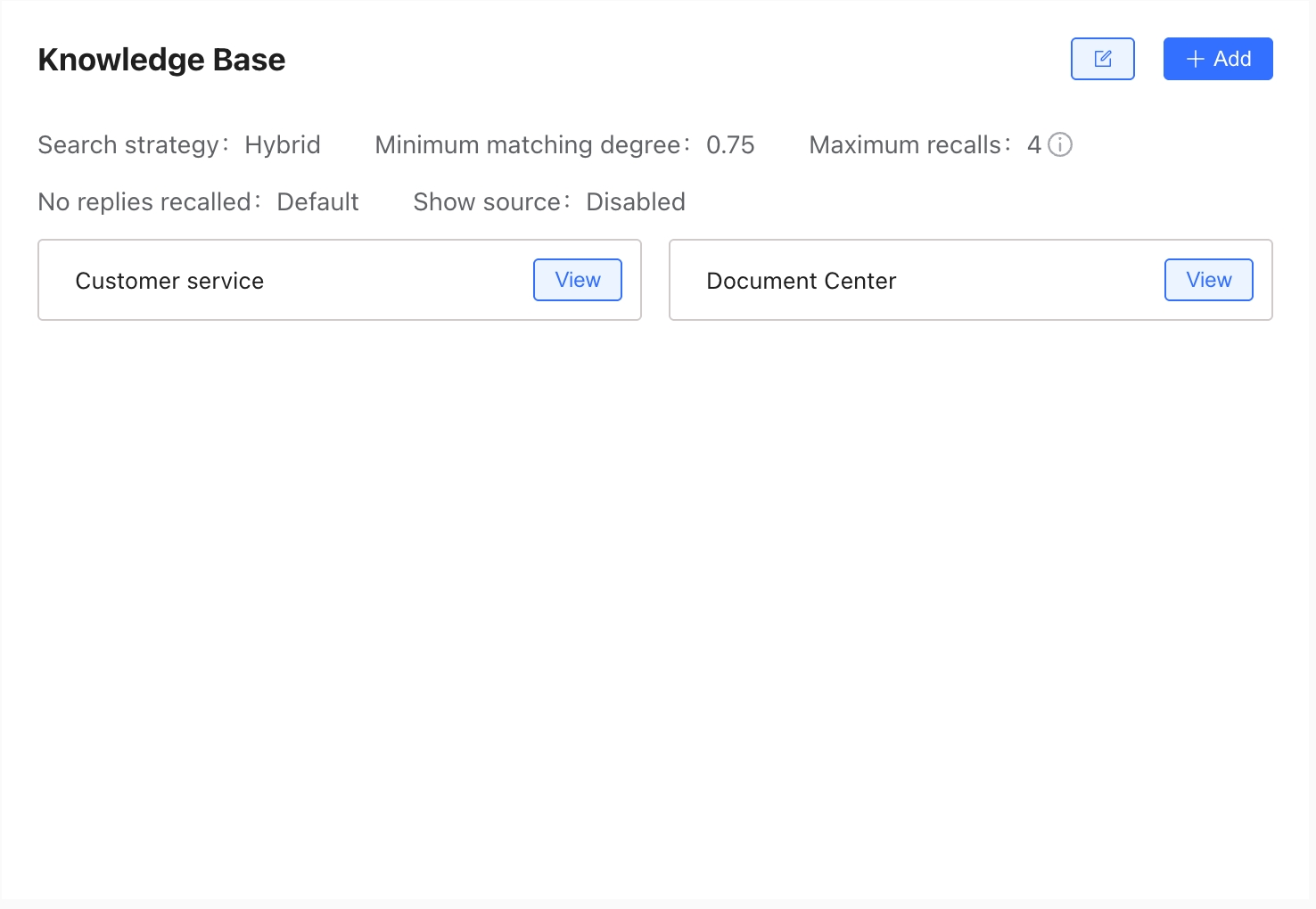
Click the edit button to modify the default knowledge base retrieval strategy. In the retrieval strategy, you can choose Semantic Retrieval or Enhanced Retrieval.
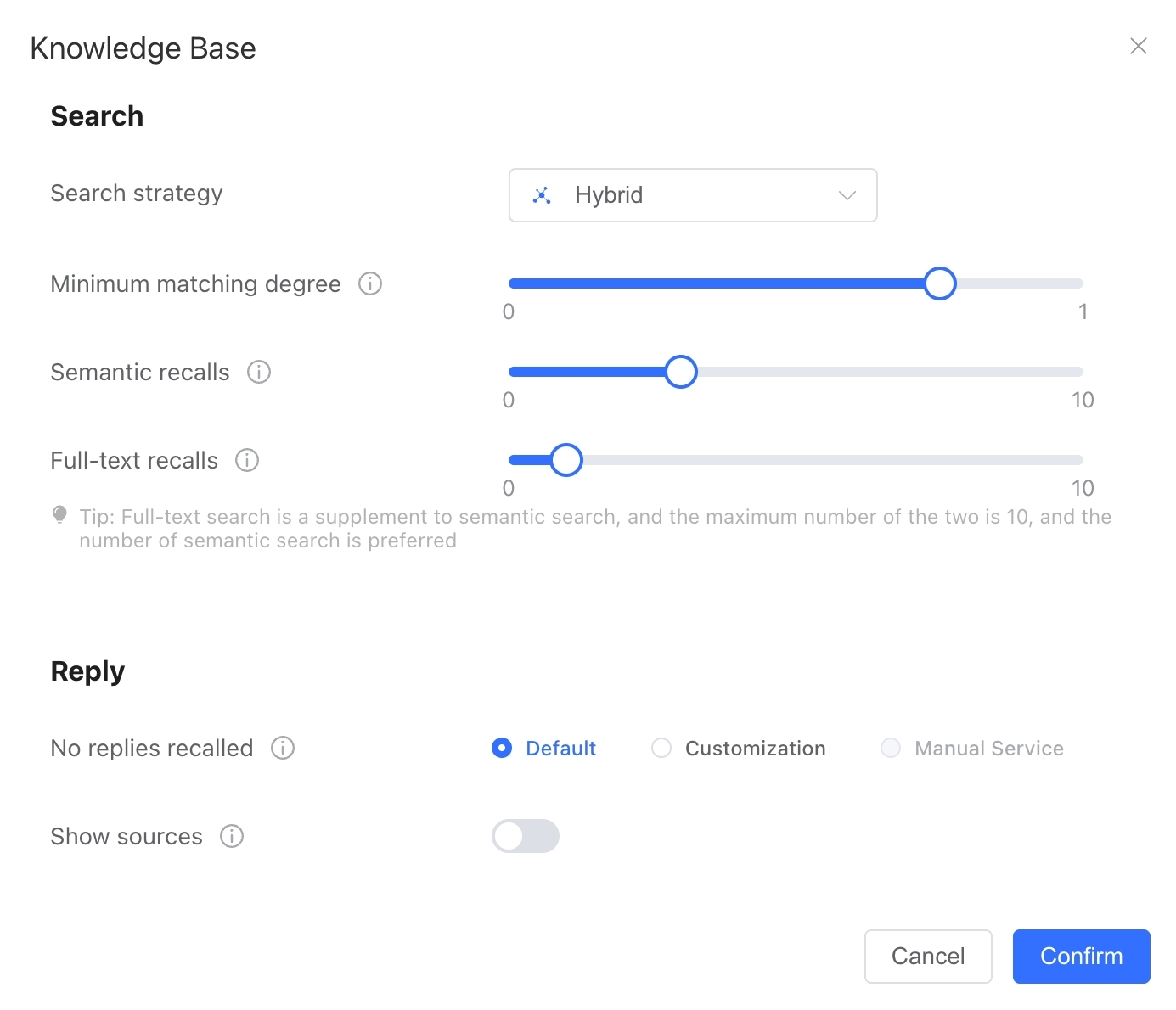
Semantic Retrieval: Matches and retrieves based on the semantic vector similarity between knowledge base corpus and user questions. Knowledge base corpus with higher semantic similarity to the question is more likely to be retrieved. When using semantic retrieval, you need to configure the semantic similarity threshold and semantic retrieval count. The former represents the minimum semantic matching similarity required for knowledge base corpus to be retrieved, while the latter represents the number of top knowledge base corpus entries to retrieve that meet the similarity threshold.
Enhanced Retrieval: Enhanced retrieval combines semantic retrieval with full-text keyword retrieval. When using enhanced retrieval, you also need to configure the full-text keyword retrieval count, representing the number of top knowledge base corpus entries containing user question keywords to retrieve.
When using full-text keyword retrieval, the system will split the user's question into several keyword groups based on common semantics, then retrieve knowledge base corpus containing these keyword groups. This method works better for knowledge base content and user questions containing names, letters, numbers, and codes (such as product model numbers).
Configuration Item Descriptions:
- Similarity Threshold: Only corpus with similarity above this threshold will be used in conversations. Setting a high similarity threshold (e.g., above 0.8) will only retrieve highly relevant knowledge, providing more accurate results but potentially missing some matches. Setting a low similarity threshold (e.g., below 0.7) may retrieve less relevant content but provides a broader retrieval range. The specific setting should be based on your corpus situation, using the Retrieval Test function to simulate user questions and select an appropriate similarity configuration based on the similarity of various corpus entries.
- Semantic Retrieval Count: The maximum number of paragraphs retrieved from the knowledge base through semantic retrieval for a single Q&A interaction. The default is 3. Generally, this count should not be set too high, as it may exceed the model's context limit and increase model token costs.
- Full-text Retrieval Count: The maximum number of paragraphs retrieved from the knowledge base through full-text keyword retrieval for a single Q&A interaction. When enhanced retrieval is enabled, the default is 1. The sum of full-text retrieval count and semantic retrieval count cannot exceed 10 (semantic retrieval count takes priority). If no keywords are matched during actual use, the full-text retrieval result may be 0.
- Miss Policy: The strategy when no content is found in the knowledge base. Options include Free Response (AI reasons and responds on its own), Fixed Text (responds based on a specified text), and Human Handoff (prompts for human handling according to the rules in Application Advanced Configuration - Human Handoff Configuration).
- Show Knowledge Base Reference Sources: When enabled, if a question matches knowledge base content, the response will display the source file name, website name, and URL of the knowledge base content (supported in both web and channel conversations). You can also set a separate similarity threshold for reference sources, so only knowledge base references above that threshold will be displayed.
If Similarity Threshold is set to 0.8 and Semantic Retrieval Count is set to 3, when a user asks a question, the content retrieved from the knowledge base will be 3 corpus entries with similarity above 0.8, which will be input to the model to generate a response.
If Similarity Threshold is set to 0.75, Semantic Retrieval Count is set to 3, and Full-text Retrieval Count is set to 1, when a user asks a question, the content retrieved from the knowledge base will be 3 corpus entries with similarity above 0.75 plus the highest-ranked corpus entry matching keywords, all input to the model to generate a response.
Note: For unstructured documents, the length of each corpus entry is what we set during import, defaulting to 500 characters. For Q&A structured documents, the corpus length is the sum of the question and answer. This allows you to roughly estimate the length of knowledge base content carried in each question, which cannot exceed the model's maximum context length setting.
6. Retrieval Testing
During knowledge base use, if you have questions about the retrieval results for certain cases, you can simulate user questions on the Retrieval Test page of the knowledge base configuration to view the knowledge base retrieval results. Retrieval testing supports both Semantic Retrieval and Enhanced Retrieval modes:
6.1 Semantic Retrieval
Retrieves based on the semantic vector similarity of knowledge base corpus, with each corpus entry showing a similarity indicator representing its relevance to the question.

6.2 Enhanced Retrieval
Combines semantic retrieval with full-text keyword retrieval, showing retrieval results and similarity indicators (or relevance ranking) from both methods to represent the relevance of each corpus entry to the question.
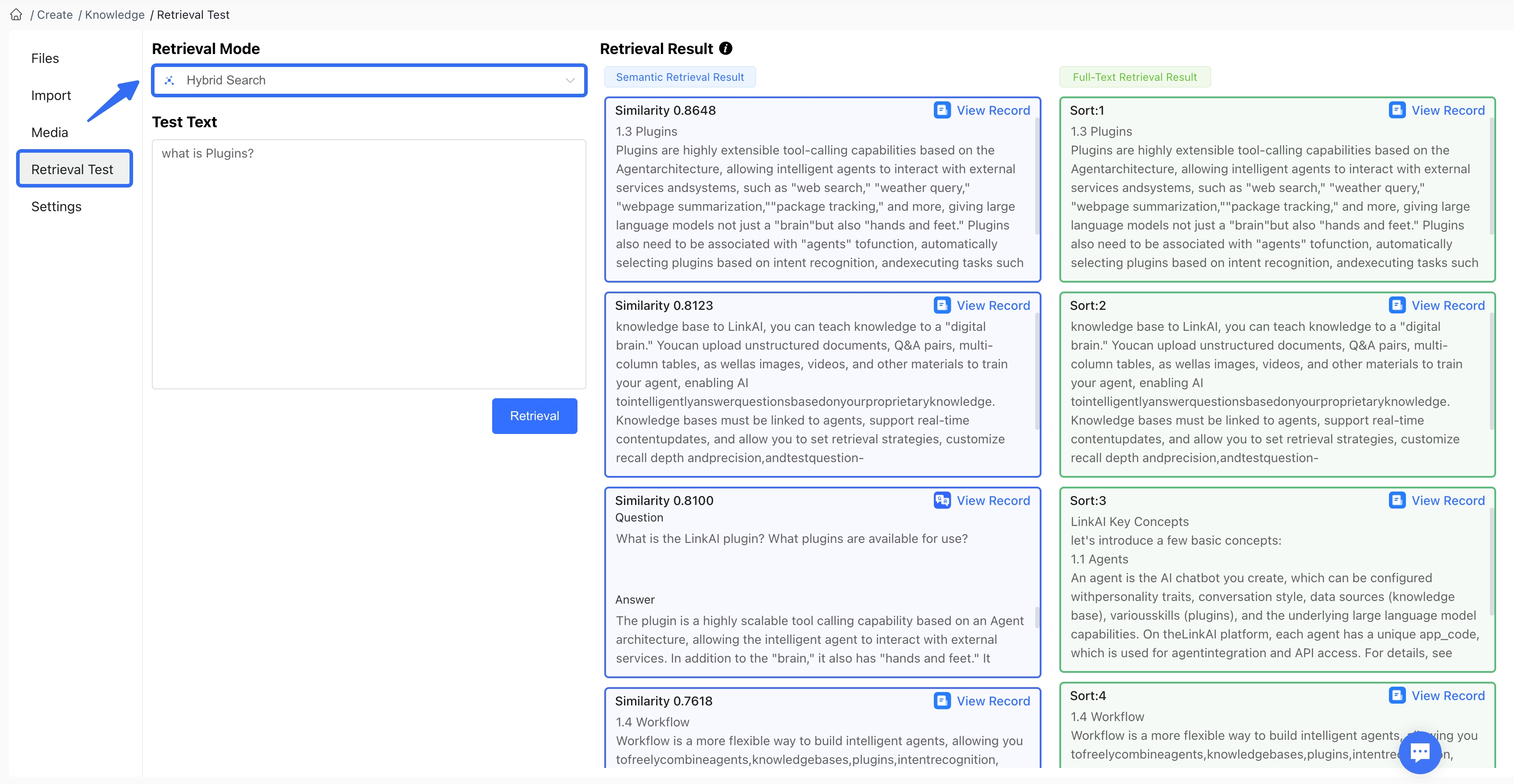
The knowledge base retrieval test results can help adjust knowledge base retrieval strategy configurations.